From Online Behaviours to Images: A Novel Approach to Social Bot Detection
In this post, I want to share the content of a paper that was recently accepted for publication at ICCS1.
Introduction
With the advent of the internet and Online Social Networks (OSNs), production and fruition of information feature less mediated procedures, where content and quality do not always go through a rigorous editorial process. Although OSNs make our lives easier by giving us immediate access to informa- tion and allowing us to exchange opinions about anything, the danger of being exposed to false or misleading news is high. The promotion of disinformation on OSNs has often been juxtaposed with the existence of automated accounts known as bots. The struggle between bots hunters and bots creators has been going on for many years now, and the actions of these automated accounts with malicious intent have influenced even the purchase of Twitter itself – just remember the $44 billion deal that went up in smoke precisely because of concerns about the unquantified presence of bots on the platform.
In this work, we exploit the digital DNA which represents the sequence of actions of an account. Thus, we propose an algorithm to transform sequences of digital DNA into images and we run pre-trained Convolutional Neural Networks (CNNs), such as VGG16, ResNet50, and WideResNet50 over the generated images.
Digital DNA
The biological DNA contains the genetic information of a living being and is represented by a sequence which uses four characters representing the four nucleotide bases: A (adenine), C (cytosine), G (guanine) and T (thymine). Digital DNA is the counterpart of biological DNA and it encodes the behaviour of an online account. In particular, it is a sequence consisting of L characters from a predefined alphabet:
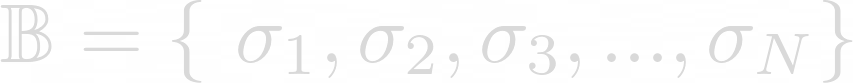
In the above equation each σ is a symbol of the alphabet and a digital DNA sequence will be defined as follow:

Each symbol in the sequence denotes a type of action. In the case of Twitter, a basic alphabet is formed by the 3 actions representing the types of tweets:
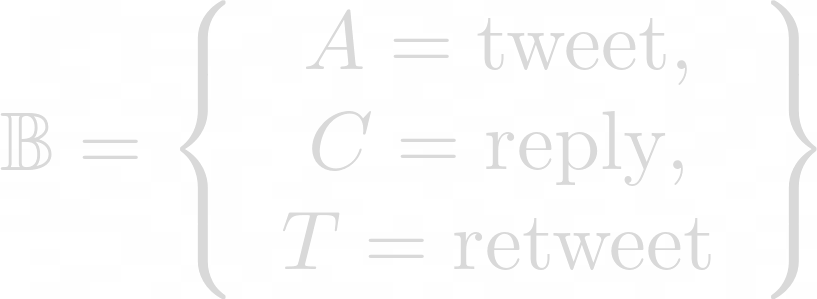
According to the type of tweets, it is thus possible to encode the account timeline, which could be, e.g., the following s = ACCCTAAACCCCCCTT.
The new Algorithm
Since CNNs expect images of the same size, we first consider the string of maximum length and check whether the length is a perfect square. If not, we consider the perfect square closest to and strictly largest than the maximum length. By doing so, it is possible to transform all the strings to images of equal size. After arbitrarily deciding a RGB color to assign to each symbol in the alphabet, the image is colored pixel by pixel based on the coors assigned to the correspondent symbol. The coloring is done as long as the length of the input string is not exceeded; therefore, if the sequence is not the one with the max- imum length, this will result in a black part of the image. All images created are in grayscale; we tried also with colored images, but there was no significant improvement in the final results. More details, such as the algorithm’s pseudocode, are in the paper.
Results
We tested our new approach on different datasets: Cresci-2017, Cresci-stock-2018 and TwiBot20. I will show just some image from Cresci-2017, you can read more, if interested, in the paper.


These two images, representing a bot (left) and a genuine (right) account resp., show a difference: some noise in the right figure distinguishes this account from that of the bot. Intuitively, a CNN is able to pick up these differences and, thus, classify the accounts in the correct way.
Since I don’t want to spoil the results we got (they are good!), I recommend to check them directly in the paper 😄. Here you can find the presentation.
Finally, I want to thank my supervisor, prof. Angelo Spognardi, for giving me the opportunity to go and present this work!
-
GGS Rating: B – CORE:A, LiveSHINE:B, MA:B. ↩